Porting One Hour One Life's Game Loop to CKB
Following my Teeworlds port, which showcased MOBA / fighting games on chain, I started another quest: porting the game loop of One Hour One Life (OHOL for short) by Jason Rohrer to the CKB blockchain.
OHOL is a multiplayer survival game of parenting and civilization building (or one can think of it as a MMORPG). The port is powered by CKB-VM, a deterministic RISC-V-based virtual machine used by CKB to validate on-chain programs.
A demo of this unofficial port can be found here. I’m still polishing the code, so unfortunately the source code is not yet available. However, I do have a MockTransaction tx file available. So you can try running the game loop in ckb-debugger:
$ unzip ohol_on_ckb_tx.zip
$ ckb-debugger --tx-file ohol_on_ckb_tx.json --cell-type input -i 0 -s type
(logs omitted...)
Script log: [INFO] CKB: canonical hash verified
Run result: 0
All cycles: 198217586(189.0M)
The transaction has one input cell (CKB’s basic state container, roughly analogous to a UTXO) with an always-success lock script (a RISC-V program, here we use a dummy one for the demo), and a type script (another RISC-V program) that runs the OHOL game loop, reading the game tape from the transaction’s witness field.
One note is that the OHOL game loop binary is actually ~6.1MB in size. For a debugger used binary this is fine, I’m attaching the binary with debugging information, so profiling it does reveal bottlenecks. When debug information is stripped, the OHOL game loop binary will be ~462KB, well within CKB’s limits (CKB requires all transactions to be no larger than 512KB).
The test transaction runs one minute of OHOL gameplay, replicating all game logic in ~198.2 million CKB cycles, or ~113 million RISC-V instructions. (CKB cycles are CKB-VM’s metering unit, conceptually similar to gas on Ethereum — every instruction costs a small, fixed number of cycles, and a transaction has a cycle limit.) I also gathered some memory usage information:
=== MEMORY USAGE ===
_end (heap start): 0x26dcd7 (2546903 bytes)
brk max: 0x400000 (4 MB)
stack region: [0x0, 0x080000]
peak heap used: ~1327104 bytes (1296.0 KB) out of 1647401 (1608.8 KB) available
peak stack used: ~289936 bytes (283.1 KB) out of 524288 (512.0 KB) available
min SP: 0x039370 (at step 8954357, pc=0x0c7626)
in function: trim+0xe
Of CKB-VM’s 4MB memory space, we reserve 512KB for stack, 1604.8KB for heap. When running OHOL game loop, peak stack usage is 283.1KB (55.29%), peak heap usage is 1296KB (80.76%). I have to mention that this is a working-but-yet-to-be-heavily-optimized version. There are still bottlenecks in both computation and memory that we can address. I will get to this more later.
Please understand that this is only an unofficial, unfinished technical demo. It is not the official One Hour One Life game, and it is not affiliated with, endorsed by, or authorized by Jason Rohrer. I fully respect the terms Jason Rohrer set, and I’m deeply grateful for the incredible work he put into creating the original game, as well as making it public domain. If this ever becomes a standalone game or public service, it will use a different name and distinct branding.
Forever-running Architecture
OHOL is different from Teeworlds. The game is persistent and constantly evolving. There are no clear “game sessions”. Everyone joins the same game world, and it runs 24/7, we don’t nuke a world every 5 minutes and start from scratch.
While we are still gathering game tape like Teeworlds, we are using a slightly different workflow: every minute, all player inputs on a server are gathered and submitted on chain. A cryptographically secure world state hash is derived from the world state, i.e., all of OHOL’s game state, including the map, items on the map, player states, and other global world state. A game tape thus transitions the game from world state hash 1 to world state hash 2, and so on. Every minute a new tape is submitted on chain, updating world state hash stored on chain. The chunk in OHOL is thus one minute of wall-clock gameplay.
After defining chunk of gameplay and introducing world state hash, OHOL shares essentially the same architecture and workflow as Teeworlds:
- Modify the game loop of OHOL, so a
game tapeis dumped for eachchunk. - As a prerequisite, we introduce a feature to dump the
world stateof OHOL, which is then used to calculate theworld state hash. - We build a native
replayerfirst, abstracting all sources of data, such as player inputs, RNG sources, timestamps, etc. Given the same world state and the same tape, thereplayershould re-run the gameplay to the exact same ending world state. - We then port the
replayerfrom the native environment to CKB-VM. - When needed, profile the CKB-VM
replayerand apply necessary optimizations. - Build scaffolding code for CKB integration.
This is the same workflow as Teeworlds, with the addition of step 2. Teeworlds does not need a world state or world state hash, but a persistent world like OHOL does.
Work to Make OHOL Feasible
OHOL is a significantly more complicated game compared to Teeworlds, with rich content to make the game a joy to play. There are certain optimizations that can be deferred till we can profile OHOL properly, but there are design problems we need to work out first so OHOL can run in CKB-VM’s limited environment.
Archipelago
Fundamentally, OHOL is a grid-based game. Its giant map is divided into tiles. A tile has an X and Y position, a player walks from one tile to another, a tile can hold at most one item.
By default, OHOL’s map is really big, it uses the entire space of an int32_t value (negative values are also coordinates) to represent the X coordinate or the Y coordinate of a tile. This means OHOL by default has 4,294,967,296 x 4,294,967,296 tiles. This is way too big for CKB-VM to process.
After some calculations, I coined the archipelago idea. Each archipelago in my port is limited to the following constraints:
- 256x256 tiles
- 64 players
- 32768 items
Of course the game should never be limited to just this small grid and 64 players. The idea is we deploy one archipelago as a CKB cell on-chain, and there could well be many archipelagos. I have ideas on how archipelagos can communicate and connect to each other, but I’ll leave it to the next post where I talk more about game design changes. For now the takeaway is: by restricting one CKB cell to one archipelago, we can then process its entire gameplay in CKB-VM.
It’s worth noting that the archipelago idea is not new, similar designs have been tried by OHOL at different points in time.
Packed banks
OHOL has a list of objects and transitions encoding game logic. Objects represent, well, all the objects that exist in the game, transitions express the rules by which one object transforms into another. In OHOL they are encoded in plain txt files, and are loaded when OHOL client and server boot, but for an on-chain environment, we cannot work with this format for several reasons:
- TXT format is good for editing, but wastes a lot of space.
- Parsing and processing them for every transaction might not be the best way to do it.
I introduced PackedObject and PackedTrans structure, where we encode the same data in binary formats:
typedef struct {
int16_t id;
int16_t dummyParent;
uint16_t descFlags;
int16_t _pad2;
uint64_t flags;
float containSize;
float rValue;
int32_t foodValue;
// Some fields are omitted...
} PackedObject;
static_assert(sizeof(PackedObject) == BANK_OBJ_REC_SIZE,
"PackedObject must be 128 bytes");
typedef struct {
int16_t actor;
int16_t target;
int16_t newActor;
int16_t newTarget;
int32_t autoDecaySeconds;
uint8_t flags;
// Some fields are omitted...
} PackedTrans;
static_assert(sizeof(PackedTrans) == BANK_TRANS_REC_SIZE,
"PackedTrans must be 40 bytes");
This way we encode each object in 128 bytes, each transition in 40 bytes. It allows a more compact representation.
Even so, they won’t fit in a single CKB-VM binary. In the current version I use, OHOL has 11,402 objects (4,437 object files, plus auto-generated objects), 53,322 transitions (5,231 transition files, plus auto-generated reverse/symmetric transitions). Those require ~3.43 MB in total. Compressing them won’t help either, LZ4 brings them down to 487KB, but we’d still need to find the memory to decompress them.
In the Teeworlds post, I talked about the banked memory used by Neo Geo system. While Neo Geo only allows 1MB of P2 banked memory, it can have ROMs that are much bigger than 1MB. KOF 97 uses a 4MB P2 ROM, regions from it are dynamically loaded into banked memory at runtime.
We can do the same for OHOL. I built a tool to split objects & transitions into 500K packed bank files:
$ ls -lh cells
total 3.6M
-rw-r--r-- 1 cachy cachy 128K Jun 23 07:26 bank_bulk.bin
-rw-r--r-- 1 cachy cachy 512K Jun 23 07:26 bank_obj_000.bin
-rw-r--r-- 1 cachy cachy 512K Jun 23 07:26 bank_obj_001.bin
-rw-r--r-- 1 cachy cachy 402K Jun 23 07:26 bank_obj_002.bin
-rw-r--r-- 1 cachy cachy 1011 Jun 23 07:26 bank_sizes.h
-rw-r--r-- 1 cachy cachy 500K Jun 23 07:26 bank_trans_000.bin
-rw-r--r-- 1 cachy cachy 500K Jun 23 07:26 bank_trans_001.bin
-rw-r--r-- 1 cachy cachy 500K Jun 23 07:26 bank_trans_002.bin
-rw-r--r-- 1 cachy cachy 500K Jun 23 07:26 bank_trans_003.bin
-rw-r--r-- 1 cachy cachy 83K Jun 23 07:26 bank_trans_004.bin
We can then deploy each packed bank file on CKB as its own cell, and reference it from our transaction as a dep cell (a read-only data dependency, think of it like opening a read-only file shipped with the transaction).
We then can load needed objects & transitions on demand. In the current port, I didn’t really implement banked memory exactly like Neo Geo. Objects are loaded based on which gets used, nearby objects (by ID) are not necessarily used together. Instead I implemented a small 128-entry, 2-way associative LRU cache, where I first load objects by ID into this cache. Later matches can consult the in-memory cache directly, on a miss, we look into dep cells again. The dep cells are also designed to allow random access, so given an object ID, we know exactly its cell index and offset, and we can load it immediately via one CKB syscall (just think of CKB syscalls as file I/O).
Transitions are trickier, but we can still build a small index to allow random access into dep cells. This is where bank_bulk.bin file comes in handy, I actually pack some metadata (how many objects / transitions are available), transition index, and data that can be pre-computed into this single binary file. This includes:
- Maximum object ID and transition ID. IDs are sparse, there are actually 10,810 non-empty objects.
- categories, this is much smaller, so we pack it and load it all at once.
- All spawnable person object IDs.
- All female person IDs.
- Race information.
- All death marker object IDs.
- All edible object IDs.
- Toolset information.
Those are typically computed by OHOL at boot time. In replayer, we pre-compute them, pack them in bank_bulk.bin, so the replayer can simply load the data.
bank_sizes.h contains data hash we use to locate the bank_bulk.bin dep cell, along with the sizes of each pre-computed data section. This way precomputed data can all reside in BSS as well, avoiding heap overhead.
If you dig into the test transaction discussed above, you’ll find all of those *.bin files.
If you’ve ever shipped a game for fixed-hardware consoles (Neo Geo, GBA, PSP-era handhelds), CKB-VM will feel familiar: 4MB of RAM, a hard cycle budget, no hardware floating-point unit, no MMU, and a 512KB program-size limit. Most of the techniques in this post are not blockchain tricks — they’re console-era memory tricks, applied to a modern open-source game.
VM memory layout
To make the best use of CKB-VM’s 4MB memory space, I redesigned the whole memory layout:
- Stack lives from 0 - 512KB.
- ELF is loaded starting from 512KB.
- Heap starts from the
_endsymbol declared by ELF, and extends all the way up to 4MB.
There is actually a template following this design, you can try it out in your CKB program as well.
The layout is designed so that when stack overflow happens, it is picked up immediately as an error (SP crosses 0, becoming very large). CKB-VM has no MMU, the default layout has a small chance that stack and heap might overlap. As we are pushing towards the limits of CKB-VM, an overlap between stack and heap might lead to strange bugs and is very dangerous. With the redesigned layout, we can safely push both stack and heap to their limits. This is actually another regret of mine: I wish I had adopted this trick earlier when designing CKB-VM programs.
As mentioned above, I have employed another design: if the size of a structure is known at compile time, we should declare it as a static variable, placing it in the BSS section. Heap allocations have overhead. Some (glibc, for example) allocate more than requested, and put metadata right before the returned pointer. Some (glibc again) also add padding for alignment. Even for different allocators like jemalloc, metadata still exists, just not near the returned pointer. As we put more structures into BSS where we can, heap can be reserved for cases where it is truly needed.
Inlined settings
Apart from in-game data like objects / transitions / categories, there are also settings required by OHOL game. Some values in settings are for administration tasks, but others might affect gameplay, we need those values in replayer as well.
We can pack settings in packed bank files as well, but I want to go one step further: settings are typically loaded directly with known parameters at compile time, such as:
starvingEmotionIndex = SettingsManager::getIntSetting( "starvingEmotionIndex", 2 );
So maybe we can just scan the settings folder, and generate a C++ function that returns settings values directly like:
int SettingsManager::getIntSetting( const char *inSettingName) {
if (std::memcmp(inSettingName, "barrierBlocksPlanes", 19) == 0) {
return 1;
} else if (std::memcmp(inSettingName, "allowPeriodicPlacements", 23) == 0) {
return 0;
} else if (std::memcmp(inSettingName, "starvingEmotionIndex", 20) == 0) {
return 31;
} else if (...) {
// ... more cases ...
} else {
return 0;
}
}
But there could be hundreds of settings (I count 228 in my test), and that’s a lot of if-else-if branches to write. Luckily, perfect hash can help. Please consult this amazing lecture for more details on perfect hashing. In short, a typical hash function deals with key collisions via open addressing or hash buckets. If all the keys are known beforehand, a perfect hash lets us derive a hash function in which no collisions exist. Each key maps to its own slot, resulting in an efficient lookup table. With this trick, we can have the following:
int SettingsManager::getIntSetting( const char *inSettingName, char *outValueFound ) {
switch ( settingHash( inSettingName ) ) {
case 0x1u: // "barrierBlocksPlanes"
return 1;
break;
case 0x4u: // "allowPeriodicPlacements"
return 0;
break;
case 0x6e7u: // "starvingEmotionIndex"
return 31;
break;
// ... more cases ...
default:
return 0;
}
}
Personally I consider this a much nicer design than if-else-if branches.
We can go even further. Let’s look at a typical call site for SettingsManager:
starvingEmotionIndex = SettingsManager::getIntSetting( "starvingEmotionIndex", 2 );
We know the method, we know all the parameters of the method. Ideally, compilers should be able to strip the function call and arrive at just:
starvingEmotionIndex = 31;
This is exactly why I didn’t use the packed bank trick for settings. We don’t need CKB syscalls, we don’t even need to make C++ calls. Settings values should become direct assignments in replayer.
After marking the methods as inline to help with control-flow analysis, and with some care to keep the setting methods tidy, both g++ and clang can completely eliminate all getIntSetting calls at -O2 or higher. They can even strip the SettingsManager::getIntSetting method itself, among others. In the final replayer code, settings become direct assignments (and some of those assignments may be optimized out as well).
It’s worth mentioning that modern compilers are quite sophisticated. If we implemented the SettingsManager::getIntSetting as 200+ if-else-if branches, compilers might still be able to optimize the code away. Still, I think perfect hash makes the code more beautiful. I have to quote the memorable legend Joe Armstrong here:
Make it work, then make it beautiful, then if you really, really have to, make it fast. 90 percent of the time, if you make it beautiful, it will already be fast. So really, just make it beautiful!
Map
World state has 3 main parts:
- Map, including tile information, and items on map tiles.
- Player states.
- Other global states, such as rand sources, time, food factors, etc.
Player states and global states are trivial to track. Since we constrain each archipelago to 64 players, the storage requirement is also reasonable.
However, map is a big problem. Even when we limit an archipelago to 256x256 grid, there are still 65536 tiles to track, many of which could have items on them. OHOL has its own database engine for the map, which doesn’t fit an on-chain environment. We will have to come up with our own design here.
In addition, world state hash also requires us to be able to hash all components of a map to build a hash representing all states. Essentially, we need a map format that satisfies two requirements:
- Efficient on-chain gameplay in a compact memory region.
- Quick hashing of the entire state to build a
world state hash
First version: ECS-inspired layout
I iterated on this for a while, the first working layout I arrived at looks as follows:
#define WS_MAP_SIZE 256
#define WS_MAX_ITEMS 32768
#define WS_MAX_CONTAINERS 512
typedef struct {
int16_t objTypeID;
double decayETA;
uint16_t extra;
} WS_Item;
typedef struct {
uint8_t contCount;
int16_t containedIDs[8];
uint8_t extraData[3];
} WS_Container;
typedef struct {
WS_Item items[WS_MAX_ITEMS];
uint16_t itemFreeHead;
WS_Container containers[WS_MAX_CONTAINERS];
uint16_t containerFreeHead;
uint16_t itemID[WS_MAP_SIZE * WS_MAP_SIZE];
int16_t floorID[WS_MAP_SIZE * WS_MAP_SIZE];
double floorDecayETA[WS_MAP_SIZE * WS_MAP_SIZE];
uint8_t biome[WS_MAP_SIZE * WS_MAP_SIZE];
double chunkLookTime[WS_MAP_SIZE];
} WS_MapState;
Items require more storage, in this design, WS_Item takes 12 bytes. Not all tiles have an item, though. So for each tile we only store an itemID (2 bytes). When an item is present, the itemID field stores a slot index that points to an entry in the items array, which holds the real item data for that tile. This way only 2 bytes are needed per tile. We also cap the total items allowed in an archipelago to 32,768, reducing memory needs.
Some items are also containers requiring more storage space. We used the same trick to keep containers in a separate array, so container overhead is not paid per WS_Item. For container items, extra field in WS_Item denotes the slot index in containers array. extra is also used for some special objects but I will not elaborate since it’s irrelevant to the storage discussion.
With this design, the whole map state is ~1.2MB, we can fit it in memory. In fact, I declared the WS_MapState structure as a static variable, ensuring it resides in the BSS section. We know its size in advance, so we don’t pay any heap overhead.
Skipping WS_Item when we can
As I dug more into the development, I noticed something: not all items need a WS_Item slot. Let’s first look at WS_Item structure:
typedef struct {
int16_t objTypeID;
double decayETA;
uint16_t extra;
} WS_Item;
For those who are less familiar with OHOL, decay in OHOL terminology simply means an object can transform to another one over time. decayETA stores the timestamp when decay next happens for the object.
In fact, the majority of objects in OHOL have a decayETA of 0, they do not hold other objects or have special abilities, so they do not need the extra field either.
In addition, the maximum object ID being used by OHOL is 11,401. Even if we leave a little buffer for future game designs, it’s safe to say object ID range fits from 1 - 20000.
Finally, we only allow 32768 items.
We can thus redesign the uint16_t typed itemID:
- 0: empty, no item is stored on the tile.
- 1 - 20000: maps to the object ID of a plain item, which has a
decayETAof 0, cannot store other items, has no special abilities, soextrais unused. - 20001 - 52768: maps to a slot index, subtracting 20001 from the stored value reveals the actual slot index.
- Higher value: reserved for now.
We take advantage of the full range of uint16_t to store plain objects directly when we can. This greatly reduces the number of WS_Item slots needed. I’ve also built a tool to populate the map with more items than OHOL typically places. In an archipelago with ~25,000 items, only ~200 actually require WS_Item slots.
This also means that the 32,768-item limit only applies to items that decay, are containers, or have special abilities. Normal items don’t count against the limit.
Canonical map layout
This layout has a problem: the item on a given tile can use different slot indices in two different WS_MapState instances that still represent the same logical map. We want the world state hash to match whenever the logical map state matches. So we need a canonical form, we can’t just hash the WS_MapState structure.
As the first iteration, I used a simpler solution: iterate through each tile, for each tile, we dump the WS_Item structure when an item is present, and hash this WS_Item structure instead. Of course the actual implementation has more details:
- We need to convert plain items represented by just an
itemIdintoWS_Item, fillingdecayETAandextrawith 0. - For container items, we need to dump their contained items, hash them as well.
With those details sorted out, we get a canonical layout of the map. Differences in slot indices no longer matter.
New layout
I actually managed to get replayer working on both native and CKB-VM environments using the above map layout. But I ran into a quirk: dumping the item for every tile and hashing each one individually is quite slow. On CKB-VM, building and hashing this canonical layout into world state hash takes about 40% - 50% of all running cycles. We were spending almost as many cycles building the world state hash, as we were on actually loading and running the gameplay! That’s more than we can afford.
Some of you may have already realized that, with the new encoding for itemID, our old data structure no longer makes sense: a typical game has ~200 items that need WS_Item slots, but we are pre-allocating a 32,768-item sparse array. That does not make sense, and it wastes memory. I then switched to a slightly different design:
typedef struct {
uint16_t itemID[WS_MAP_SIZE * WS_MAP_SIZE];
int16_t floorID[WS_MAP_SIZE * WS_MAP_SIZE];
double floorDecayETA[WS_MAP_SIZE * WS_MAP_SIZE];
uint8_t biome[WS_MAP_SIZE * WS_MAP_SIZE];
double chunkLookTime[WS_MAP_SIZE];
} WS_MapStateCompact;
/* Complex item: everything beyond a plain objectTypeID.
* One per tile that needs decay, container, or grave data.
* Stored sorted by `pos` for deterministic canonical hash. */
typedef struct {
uint16_t pos; /* (y+128)*256 + (x+128) */
int16_t objTypeID; /* main object type */
double decayETA; /* main object decay (0=never) */
uint16_t gravePlayerID; /* 0 if not a grave */
uint8_t contCount; /* 0-WS_CONTAINED_CAP */
int16_t contObjTypes[WS_CONTAINED_CAP]; /* contained type IDs */
double contDecayETAs[WS_CONTAINED_CAP]; /* contained decay ETAs */
} ComplexItem;
The encoding of itemID is also changed:
- 0: empty, no item is stored on the tile.
- 1 - 20000: maps to the object ID of a plain item, which has a
decayETAof 0, cannot store other items, has no special abilities, soextrais unused. - 20001 - 65534: reserved, not used now.
- 65535: tile has a ComplexItem.
Now the compact map layout no longer has WS_Item slots, nor WS_Container slots. When an object is not a simple ID (e.g., it has decay, it is a container, it is a grave, etc.), itemID simply stores 65535 as its value. An external data structure containing ComplexItem can then be queried to locate the item for this tile. You can also see that ComplexItem has a richer structure covering all cases (decay, container, grave, etc.). Since we’ll only have a few ComplexItems, its size isn’t a concern. We can implement the container holding ComplexItems in several ways:
- A plain vector using linear scan.
- A sorted vector using binary search.
- A hash table.
This also simplifies the world state hash calculation: we can now hash WS_MapStateCompact as a whole (no more ambiguities), then hash ComplexItems in sorted order. The result is less memory used (~300KB saved), and a simpler, faster world state hash calculation.
It’s worth noting that at the moment, the port I have only uses WS_MapStateCompact when loading world state and building the world state hash. The internal gameplay still runs on the previous WS_MapState. So the ~300KB memory saving is yet to be claimed.
Other smaller techniques
Apart from migrating gameplay to WS_MapStateCompact to claim the ~300KB memory savings, there are several smaller tasks I’ve also implemented:
- LZ4 compression is applied to both the world state and the game tape. In CKB-VM, we use the minimal sflz4 to implement the decompression in compact, constant-sized memory. Thanks to the characteristics of OHOL’s data, we actually achieve very good compression ratio: the LZ4 configuration we picked (
lz4 -f -9 -B4 -BI --no-frame-crc) can compress a raw world state dump of 875KB into 42KB, a game tape of 7.1KB is also reduced to 2.4KB with the same config. - In
replayer, I skip a lot of OHOL’s code used for curses (in the port I’m trying a different game design than curses), logging, databases, server management, web stuff, etc. This work is needed so we can fit the OHOL binary into CKB’s 512KB limit. - Being designed for a native environment, SimpleVector used by OHOL tends to keep larger memory chunks to reduce allocations. It works well performance-wise in a native environment, but for a memory-constrained
replayer, it will lead to OOM quickly. I have to patch the code to allocate more conservatively. - As always, a libc/libc++ tuned for resource-constrained environments also helps a lot.
Profiling & Future Work
It’s worth mentioning the above designs and optimizations enable the game loop to run on CKB-VM. Large optimization opportunities still remain, and we can further squeeze the OHOL CKB-VM replayer to use even fewer cycles and less memory. One example has already been discussed above: we can move the gameplay code to the new map layout, freeing another ~300KB of memory. And yet there are still more optimizations we can apply:
Floating point math
Here’s an inverted stack profiling chart by samply:
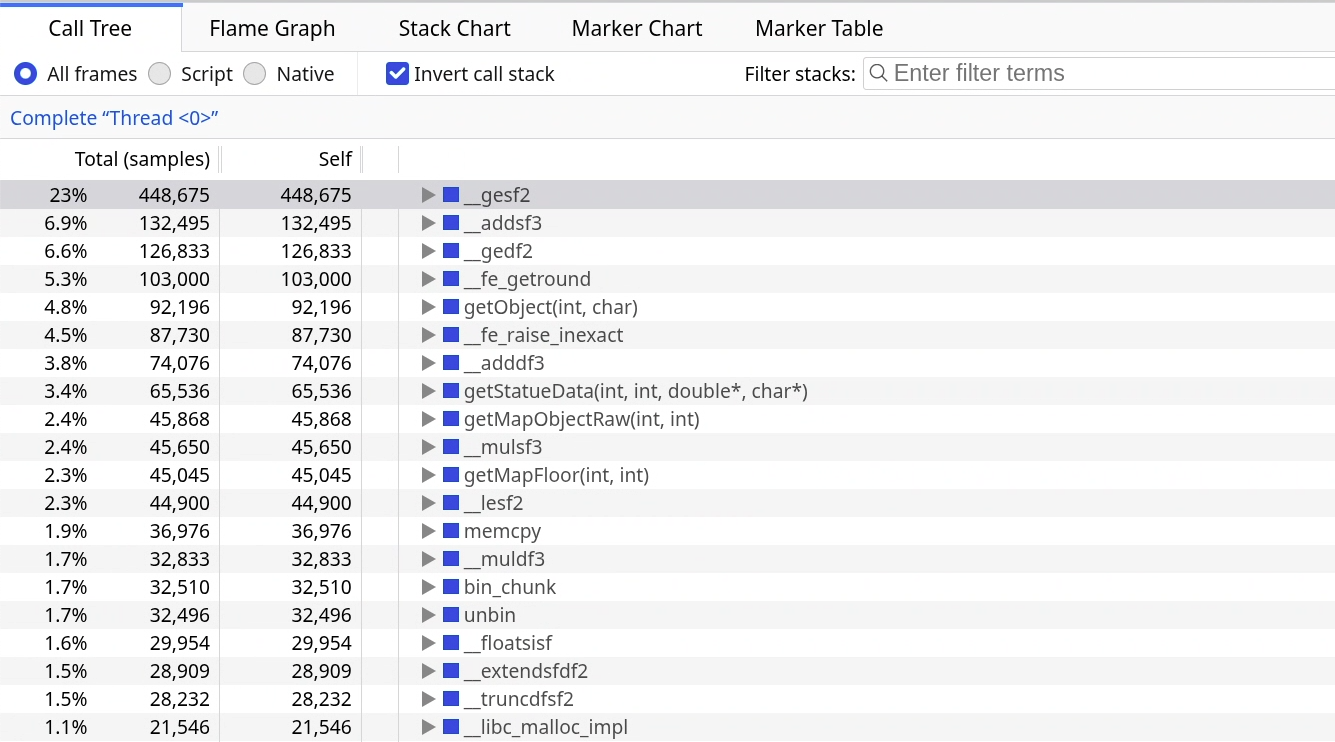
The top 4 functions __gesf2, __addsf3, __gedf2 and __fe_getround consume a total of 41.8% of all running cycles. Other functions, like __fe_raise_inexact, __adddf3 and __mulsf3 are also near the top of the list. They are all softfloat routines. OHOL uses a lot of floating-point operations, and since CKB-VM does not support hardware floating-point operations, they must all be implemented via softfloat routines. Teeworlds also uses a lot of floats, we optimized it by switching to fixed-point math. Based on the profiling chart, we should do the same for OHOL, and we can potentially save a lot of cycles. For future optimization work, floating-point math should be our No. 1 priority.
Of course, we can swap softfloat with fixed point math using fpm, just like we did for Teeworlds. Fixed point math is indeed a viable option. That said, fixed-point math certainly has its own friction, and not every game can tolerate the rounding behavior it imposes. Some games might simply say: “I don’t want fixed point math, it does not fit my mechanics.” I am actually thinking here: with some acceptable tradeoffs, could we have fast softfloat implementations that preserve floating-point semantics but run much faster? This is something I’m experimenting with, if you are interested, please stay tuned.
Compressing decay ETAs
There is one chunk of data still in our port that feels wasteful:
double floorDecayETA[WS_MAP_SIZE * WS_MAP_SIZE];
WS_MAP_SIZE is actually 256, meaning we are storing 65536 double values in memory, consuming 512KB of the precious 4MB memory. Similar to the items discussed above, some floors can also decay. floorDecayETA contains the timestamp for when next decay happens for the floor. There are vast opportunities for optimization:
- We have more compact ways to store timestamps than a full
doublerepresenting fractional seconds since epoch. For starters,floatcould be used to save bytes, and we could go even further with a compact integer-based representation. - By slightly altering gameplay, we can have nearby blocks decay simultaneously. For example, if 4 adjacent tiles all decay at the same time, we can cut the storage requirement by 4x. Even bigger savings are possible when more tiles decay together.
- Not all tiles decay, so we can also build a sparse representation, in which only decaying tiles take up storage.
There are really numerous ways to optimize it. However, with the current code we’re already at 55.29% peak stack usage and 80.76% peak heap usage. The floorDecayETA array can serve as a buffer we can shrink later, when we need more room for richer gameplay or higher capacity. It’s actually a common trick from the old days, where programmers would set aside a large static array hidden somewhere in the binary. Then days before shipping, when they couldn’t fit the release build into memory, they’d simply delete the hidden array to free enough space to make the game fit. floorDecayETA can serve as exactly that kind of secret stash, ready when we need it.
I’m sure as we profile more, more opportunities will appear. The bottom line is: even with a game as rich as OHOL, we are still well within CKB-VM’s cycle & 4MB memory limits.
Next
This post covers most of the technical challenges we ran into to port OHOL game loop to CKB-VM. Just like in the archipelago section, fitting the OHOL game loop into CKB-VM requires us to make tradeoffs and impose restrictions on OHOL. That said, I do believe a blockchain, when used right, can also foster new gameplay ideas. In the next post, I will share how I plan to build on the archipelago design and explore new OHOL-inspired gameplay ideas.